
앞선 포스팅에서 말했듯이 우리 조는 디자인이나 넣을 데이터들이 모두
정해진 상태에서 백엔드 구성에 들어갔기 때문에,
ERD를 구성하기에도 생각보다 편하게 작업에 들어갔다.
ERD
ERD 작성 툴은 가장 깔끔하다고 판단한 ERD Cloud를 사용했고,
팀원과 같이 ERD를 구성했기 때문에 Team ERD를 사용하여 같은 시간에 함께 작성을 했다.
ERDCloud
Draw ERD with your team members. All states are shared in real time. And it's FREE. Database modeling tool.
www.erdcloud.com
우리 팀의 전체적인 ERD 구성은 다음과 같다.
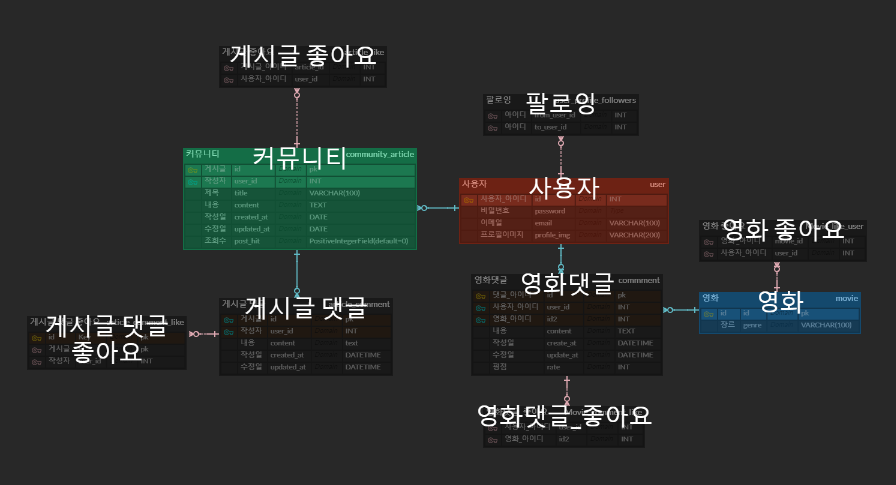
(실제 백엔드 구성과는 일부 차이가 있을 수 있다.)
이제 ERD를 하나하나 살펴보도록 하자.
(사실 ERD 작성법을 제대로 파악한 상황이 아닌 상태에서, 전체적인 데이터베이스 구성을 짜려고 했기 때문에,
연결 선들이 정확하지 않을 가능성이 크다.)
사용자
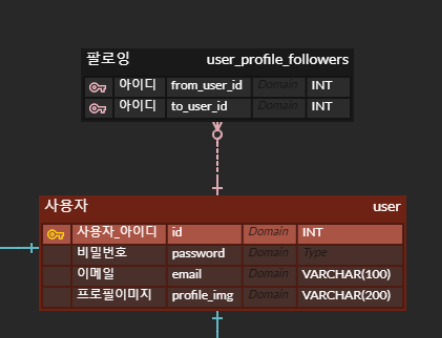
사용자 파트이다.
가장 기본인 로그인, 회원가입을 위한 이메일, 비밀번호
닉네임으로 사용하기 위한 사용자 아이디, 그리고 프로필 이미지를 넣기 위한 프로필 이미지를 구성해주었다.
또한
사용자간 팔로우 기능을 넣고자 했기 때문에, 사용자 아이디를 연결한
팔로우 파트를 따로 만들어 주었다.
게시글
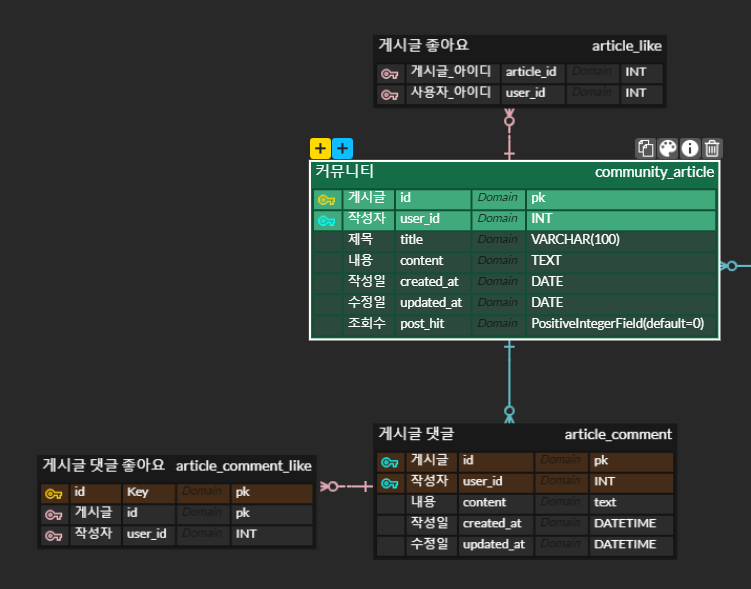
커뮤니티의 게시글 파트이다.
모든 게시글은 사이트를 이용하는 사용자에게 작성자, 내용, 작성일, 수정일, 조회수 등의
여러 정보를 제공할 수 있도록 ERD를 구성해놓았고, 해당 게시글에 대한 좋아요 기능.
게시글에 달린 댓글에 대한 ERD, 그 댓글들을 좋아요 할 수 있도록 따로 ERD를 또 구성해 보았다.
영화
고민을 가장 많이 한 파트가 아닐까 싶다.

딱 보는 순간 영화 데이터는 도대체 어디에 있는거지란 생각을 하게 된다.
우리가 현재 입장에서 긁어올 수 있는 영화 데이터는 대략 3만개 정도 되었고,
이 3만개라는 데이터 수가 전체 영화 수에서는 턱없이 부족하다는 판단이 들었다.
따라서 검색을 하게 되는 영화의 데이터는 영화 데이터를 제공하는 API인 TMDB에서 데이터를 가져와 보여주고,
우리는 한번 가져온 영화 데이터에 대한 댓글과, 좋아요만 관리하는 식으로 백엔드를 짜기로 결정했다.
그 이외에는 해당 영화에 대한 좋아요, 댓글, 댓글에 대한 좋아요 등에 대한 ERD를 작성해주었다.
ERD를 구성할 때, 데이터를 어떠한 식으로 구성해야 가장 효율적이고,
우리가 어느정도의 데이터 양을 초반에 확보할 수 있을지가 가장 논점이 되었던 것 같다.
실제로도 우리와 같은 식으로 데이터를 구성했을 경우,
찾을 수 있는 영화의 개수는 TMDB가 가지고 있는 모든 영화가 되기 때문에 거의 모든 영화를 찾을 수 있었고,
영화 데이터를 많이 확보해 놓지 않은 사이트의 경우에는 내가 찾는 영화가 없는 경우가 많았다.
ERD를 구성하고 난 뒤에는,
백엔드 작업에 착수했고, 우리는 rest api를 이용한 웹페이지를 구성하려 했기 때문에,
백엔드에서는 serializer가 주 쟁점이 되었다.
'프로젝트 > Eivom' 카테고리의 다른 글
| [Eivom] 5. 프론트엔드 구조 및 정리 (0) | 2022.06.09 |
|---|---|
| [Eivom] 4. DRF를 이용한 백엔드 구성 (0) | 2022.06.08 |
| [Eivom] 2. 초기 디자인 기획 (0) | 2022.06.07 |
| [Eivom] 0. 영화 추천 + 커뮤니티 사이트 (0) | 2022.06.07 |
| [Eivom] 1. 초기 기획과 전체적인 방향 잡기 (0) | 2022.06.07 |



